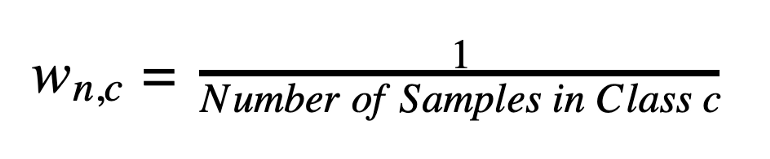Class Weight Class weight는 전체 학습 데이터에 대해서 클래스별 가중치를 계산하는 방법으로 같은 클래스 내의 데이터 샘플은 같은 weight를 갖는다. 클래스 A에 해당하는 class weights는 sklearn이 제공하는 compute_class_weight 로 계산할 수 있다. 간단히 이야기하면 클래스별 샘플의 역수가 크 클래스의 weight가 된다. 이 방법 이외에 Sample Weight 개념적으로는 class weight와 동일하지만 전체 배치가 아니라 미니 배치 상에서 sample의 수를 고려해서 loss를 계산해주는 방법이다. . 아래의 블로그에서 소개한 방법은 크게 3가지이다 1. INS. (Inverse of Number of Samples) 배치 내에서의 sampl..