2021. 01. MicroSoft에서 발표한 딥러닝 앙상블 기법의 이론적 근거가 되는 논문 "Three mysteries in deep learning: Ensemble, knowledge distillation, and self-distillation"
컵퓨터 비전 데이터셋에서 모델은 객체를 여러관점을 통해서 분류하는데, 예를 들어 자동차 이미지를 헤드라이트, 바퀴, 창문의 특징을 통해서 분류할 수 있다. 신경망은 random seed 값에 따라서 이러한 관점 중 일부 집합만 빠르게 학습하여 클래스를 분류한다. 즉, 모델이 헤드라이트 하나만 사용해서 자동차를 분류해도 정확도 면에서 충분할수 있다. 이러한 상황에서 앙상블은 큰 힘을 발휘한다 !
개별신경망들이 각자 다른 관점으로 특징을 학습하고 개체를 분류하기 때문에, 이것들을 합치면 종합적인 판단이 가능한 것이다.
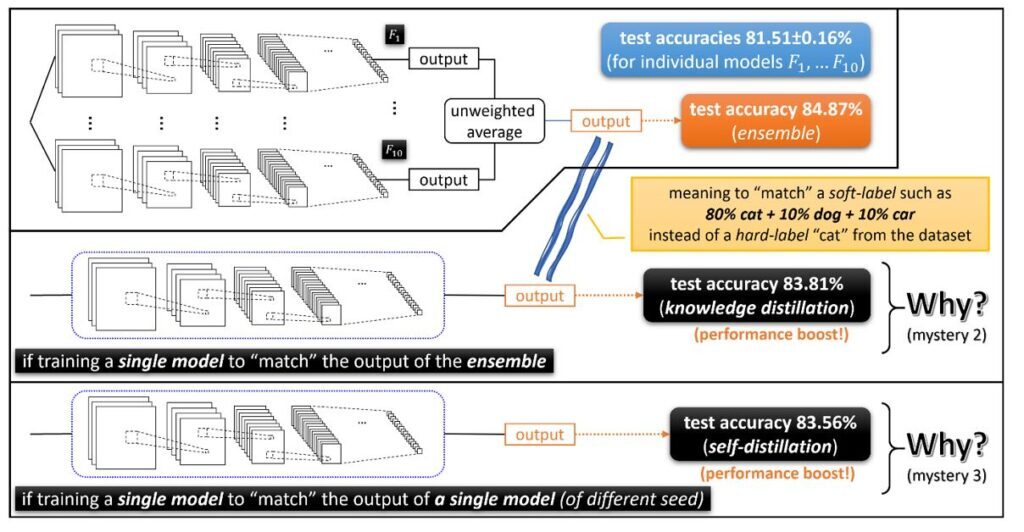
Mystery 1: Ensemble.
1) F1....F10까지 더하고 10으로 나누어 주는 것 --> performance boost disappear
2) unweighted average of the outputs of these independently trained networks --> huge boost
두 가지의 방법이 어떻게 다른 것인가 ? (찾아보기)
Mystery 2: Knowledge distillation.
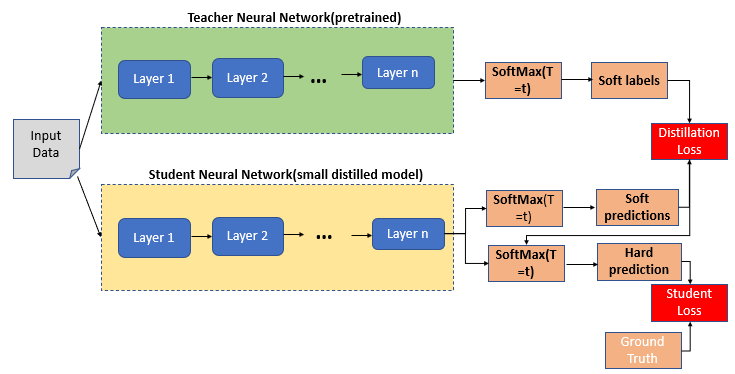
-앙상블이 test accuracy를 높일 수 있지만, 10배이상의 inference time이 발생한다. Low-energy가 앙상블의 문제점이기 때문에 Knowledge Distilation 방법이 제시되었다. Knowledge Distilation 방법은 단순히 개별 모델을 학습하고 앙상블의 output 결과를 매칭한다.
Mystery 3: Self-distillation.
Implicitly combining ensemble and knowledge distillation
Training an individual model to match the output of another identical individual model(but using a diffrent random seed) somehow gives a performance boost

3 deep learning mysteries: Ensemble, knowledge- and self-distillation
Microsoft and CMU researchers begin to unravel 3 mysteries in deep learning related to ensemble, knowledge distillation & self-distillation. Discover how their work leads to the first theoretical proof with empirical evidence for ensemble in deep learning.
www.microsoft.com